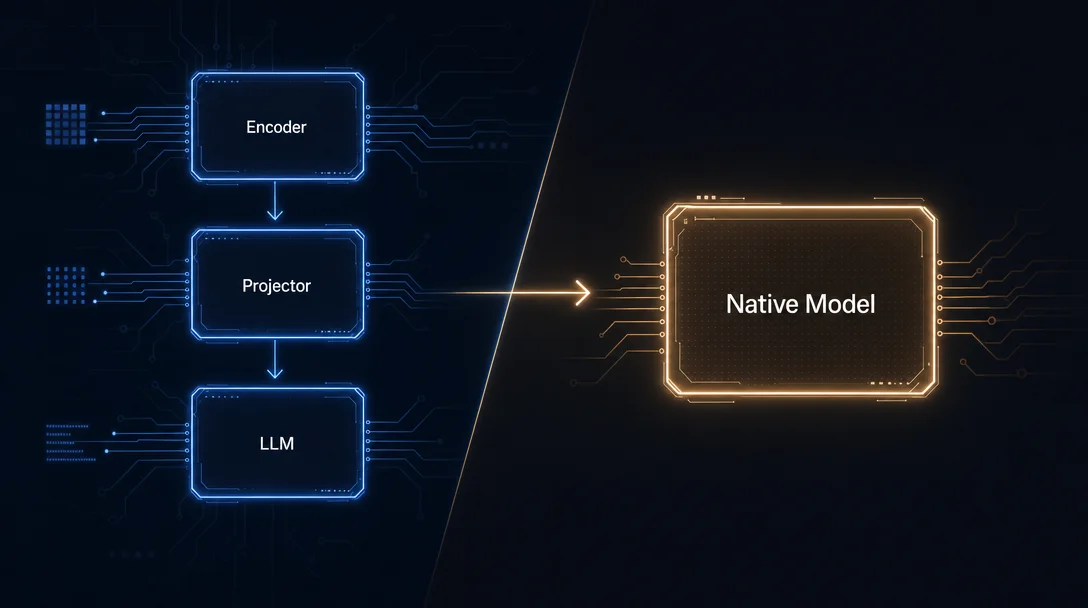
Vision encoders are the next pipeline to die
NEO-ov (arXiv:2605.28820) is the first open-source proof that encoder-free native VLMs match modular counterparts at 7–9B scale — with a decisive spatial reasoning advantage (90.0 vs. 29.6 on Mindcube). GPT-4o and Gemini made this move in 2024; the open-source option now exists. Three PM decisions for routing features to native vs. modular today.

On May 22 this brief covered native audio models replacing the STT→LLM→TTS pipeline. The same structural argument is playing out in vision. The dominant multimodal Vision-Language Model (VLM) architecture today — a pretrained visual encoder like CLIP or SigLIP feeding compressed representations into an LLM via a projector — is facing the same question the audio pipeline faced: what happens when a single end-to-end model beats the stack on its own terms?
A paper from NTU's S-Lab and SenseTime Research published May 27 provides the clearest evidence yet that it already does. 1 NEO-ov (arXiv:2605.28820) is an encoder-free Vision-Language Foundation Model that handles single images, multi-image reasoning, video, and spatial intelligence in one unified decoder-only backbone — and at the 9B scale matches modular Qwen3-VL (a Transformer with a dedicated vision encoder) on most benchmarks while beating it significantly on spatial reasoning.
Why modular VLMs have a structural ceiling
The modular design isn't just an architecture choice — it carries specific engineering constraints that the authors of NEO-ov document in the paper's opening section. 1
Three friction points stand out:
- Flexibility: Pretrained image encoders like CLIP are optimized for static frame-level representations. Video encoders over-emphasize temporal dynamics. Neither handles the full range of single-image, multi-image, video, and spatial tasks cleanly.
- Efficiency: Decoupled vision and language modules fragment training and generate large post-alignment overhead. Streaming video inference can't use KV caching on the encoder side — extending a visual encoder to long video is expensive.
- Scalability: You need to balance the visual encoder's capacity against the LLM's capacity separately. More parameters in the encoder don't automatically improve the LLM's downstream reasoning.
The deeper issue: "Language models reason over semantically filtered representations rather than native visual signals, limiting fine-grained perception and precise geometric reasoning." 1 Pretrained encoders (CLIP, SigLIP) discard texture, local geometry, and fine spatial structure because their training objective is text-image semantic alignment, not pixel fidelity. The LLM never sees the original pixels.
What NEO-ov actually proves
NEO-ov replaces the encoder entirely. Visual input goes through a lightweight patch embedding (two convolutional layers, each visual token covers a 32×32 image region) and enters the same decoder-only backbone alongside text tokens. 1 Two architectural additions handle the multimodal structure:
- Pre-Buffer layers (12 layers for the 2B model, 6 for the 9B): specialized early layers that develop pixel-pixel and pixel-word associations before the full LLM processes them
- THW decoupled attention + Native-RoPE: separate attention heads for temporal (T), height (H), and width (W) dimensions with position encoding tuned to each axis — spatial and temporal structure emerges natively inside the backbone rather than being injected by an external encoder
The benchmark results, compared against same-scale modular VLMs at 2B and 9B parameter counts:
| Benchmark | NEO-ov 2B | Qwen3-VL 2B | NEO-ov 9B | Qwen3-VL 9B |
|---|---|---|---|---|
| MMMU (general VQA) | 54.7 | 53.4 | 68.1 | 69.6 |
| MMBench | 80.0 | 78.4 | 85.1 | 84.5 |
| HallusionBench | 81.4 | 76.9 | 85.4 | 85.7 |
| Mindcube (spatial) | 77.2 | 34.2 | 90.0 | 29.6 |
| DocVQA (OCR) | 83.0 | 88.1 | 91.9 | 96.1 |
| VideoMME | — | — | 67.4 | 71.4 |
Two findings stand out. First, NEO-ov's spatial intelligence advantage is large: the 9B model scores 90.0 on Mindcube vs. Qwen3-VL's 29.6 — the highest of any general-purpose VLM tested. The authors' explanation: native pixel-to-pixel interactions in the Pre-Buffer allow the model to preserve fine geometric structure that an encoder would compress away. 1 Second, OCR and long-video remain genuine gaps — DocVQA (91.9 vs. 96.1) and MLVU (69.3 vs. 78.1 for Qwen3-VL; MLVU is a long-video understanding benchmark testing retrieval and reasoning across extended video clips). The authors attribute this to training data scale and quality, not architecture — which means these gaps are expected to close as native VLMs get more OCR-heavy training data.
Where the field stands
The split between native and modular architectures now maps cleanly across the main VLMs:
| Model | Architecture | Native since | Key tradeoff |
|---|---|---|---|
| GPT-4o (OpenAI) | Native | May 2024 | Closed; 320ms avg latency 3 |
| Gemini 1.0+ (Google) | Native | Dec 2023 | Closed; 1M context window 4 |
| Chameleon (Meta) | Native | May 2024 | Open; image generation + understanding 5 |
| NEO-ov (S-Lab NTU + SenseTime) | Native | May 2026 | Open; understanding-only; weak on OCR 1 |
| Claude 3/4 (Anthropic) | Modular | — | Closed; strong OCR/documents |
| Qwen3-VL (Alibaba) | Modular | — | Open; best-in-class OCR/video |
| InternVL3.5 (OpenGVLab) | Modular | — | Open; strong general VQA |
OpenAI explicitly made the native argument on launch: "With GPT-4o, we trained a single new model end-to-end across text, vision, and audio, meaning that all inputs and outputs are processed by the same neural network." 3 The SenseTime team behind NEO-ov's precursor put it more directly: "Multimodal AI is no longer about connecting systems. It's about building one that was never divided." 6
PM decision path
If your feature is spatial, hallucination-sensitive, or multi-image: native is already better. Spatial features (AR anchoring, floorplan analysis, 3D product visualization) are where the 3× Mindcube gap matters directly. Hallucination-sensitive pipelines (medical image description, content moderation, legal document review) benefit from NEO-ov's stronger HallusionBench scores — HallusionBench measures whether a model makes up visual details not present in the image. Multi-image reasoning (e-commerce product comparison, multi-frame video understanding) is a natural fit for the cross-image attention native architecture enables.
If your feature is OCR, document extraction, or long-video: modular is still better, and that's where Qwen3-VL and Claude Vision have a real edge today. Don't switch for the sake of architecture — the data gap is about 4 points on DocVQA, which is large enough to matter in production.
For teams that want to run open-source: NEO-ov is available today under Apache 2.0 — both NEO1_5-2B-SFT and NEO1_5-9B-SFT are on HuggingFace. 7 The prior NEO work required only 390M image-text pairs to train from scratch — comparable or below typical modular VLM pretraining requirements. 8 A self-hosted 9B native VLM is now a realistic option for teams that need custom fine-tuning and can't route through a third-party API.
Two things to watch: First, whether the OCR gap closes in the next NEO iteration — the paper's own analysis says it's a data problem, which the team can fix without architectural changes. Second, the SenseNova-U1 fork of this architecture 9 extends native VLMs to image generation as well — the same encoder-elimination logic applied to outputs, not just inputs. That's a roadmap for products that need both understanding and generation in one model call.
コンテンツカードを読み込んでいます…
参考ソース
- 1From Pixels to Words — Towards Native One-Vision Models at Scale
- 2NEO-ov Benchmark Results
- 3Hello GPT-4o
- 4Introducing Gemini 1.5
- 5Chameleon: Mixed-Modal Early-Fusion Foundation Models
- 6NEO-unify: Building Native Multimodal Unified Models End to End
- 7NEO Series: Native Vision-Language Models from First Principles
- 8NEO: Native Vision-Language Primitives (ICLR 2026)
- 9SenseNova-U1: Unifying Multimodal Understanding and Generation
このコンテンツについて、さらに観点や背景を補足しましょう。